Hirdetés
-


Spyra: nagynyomású, akkus, automata vízipuska
lo Type-C port, egy töltéssel 2200 lövés, több, mint 2 kg-os súly, automata víz felszívás... Start the epic! :)
-


Computex 2024: monstrumhűtő a DeepCoolnál (videóval!)
ph Az Assassin IV széria legújabb verziója egy vapor chamber talpat kapott, így már 300 wattig használható.
-


Filléres Redmi érkezett
ma Az A3x nem kapott nagy bemutatót, egyszer csak felbukkant.






Új hozzászólás Aktív témák
-
#551
 EQMontoya
veterán
DrojDtroll
#550
EQMontoya
veterán
DrojDtroll
#550
EQMontoya
veterán
válasz
 DrojDtroll
#550
üzenetére
DrojDtroll
#550
üzenetére
Nem.
Sok okból nem, de talán a legfőbb, hogy a cmd csak akkor adja át az argumentumot a programodnak, amikor lenyomod az entert. Tehát addig semmilyen interakciót nem tudsz létrehozni.
A google és hasonló megoldások (intellisense pl.) nyilván eventek alapján működnek egy adott kódon belül.
Egyébként az autocomplete egy elég bonyolult dolog, ha nem vagy túlzottan gyakorlott programozásban, akkor elég komoly fába vágtad a fejszét.
Címkereséshez írtunk anno smartkeyboardod (gyakorlatilag ugyanaz a lényeg, mint itt: csak azokat a billentyűket hagyni aktívan, amelyekkel folytatódhat a cím), és ez rohadtul nem egy triviális dolog.Same rules apply!
-
#554
 DrojDtroll
addikt
DrojDtroll
addikt
DrojDtroll
addikt
Végül egy ilyen megoldást kaptam. Elég jól működik. Az meg nem zavar hogy kell hozzá a shell, mert úgyis linux alá kell a dolog.
[ Szerkesztve ]
-

tvamos
nagyúr
válasz
 cousin333
#549
üzenetére
cousin333
#549
üzenetére
Koszonom, hogy probalsz segiteni!
Igen, olyasmire gondoltam, csak nem szretnem kifizetni a LabView-t, meg tetszik a Python, szeretnem egy kicsit megtanulni.
Igen, valodi muszerek vannak, van gyari, meg sajat fejlesztesu (penzhianybol kifolyolag, mivel nincs mindig par millio egy Agilent, Tektronix, stb. muszerre, de nem kell nagyon komoly dolgokra gondolni, egy-ket kis MCU-s kapcsolas, log a soros porton, ilyesmi) is, ezeket probalom automatizalni, szinkronizalni a merest kulso esemennyel, a meresi ertekeket lementeni gepre.
"Mindig a rossz győz, és a jó elnyeri méltó büntetését." Voga János
-
tvamos
nagyúr
válasz
cousin333
#556
üzenetére
Tavaly QT-vel szenvedtem, de aztan kiderult, hogy lehet ezt ugyesebben is, de akkor kifutottam a projekttel az idobol, es elakadt a tanulas.
Most szeretnek a ugy nekiindulni, hogy mar valami egyszerubb megoldast hasznalok.
A konkret feladat az lenne, hogy a gep elinditja a tapegyseget egy uzenettel a soros porton, olvassa a poton, amit kuld egy VA mero, es amikor eloall a trigger feltetel, akkor olvasna az oscilloscope-omat. Ez nagyjabol meg is van, menti a meresi eredmenyeket idobelyeggel.
A gond az, hogy kene valami perzisztencia kijelzest irni, mert mindig excelben csinalni az nem annyira jo. Persze, mukodik, es jo is, meg miden, csak megis na, jo lenne valami realtime kijelzes.
Szeretnem a vegen az egeszet PC-rol RPi-re portolni. Szoval Linuxos felulet igazan jo lenne, de igazabol az lenne a legjobb, ha Linuxon, meg Windowson is menne a programom. Itt egy kicsit elvesztem a soros port kivalasztasaban. Jo lenne azt is GUI-n...[ Szerkesztve ]
"Mindig a rossz győz, és a jó elnyeri méltó büntetését." Voga János
-

cousin333
addikt
Tehát az első mondatodban QT helyett Tk-t kell érteni?
A helyzet az, hogy a GUI egy olyan téma, amit én is kerülgetek, mint a forró kását. Inkább az egyszerűbb, "szkriptesebb" irányba mentem el, ami az IPython Notebook (újabb nevén Jupyter Notebook) használatát jelenti a klasszikus adatgyűjtés-feldolgozás-ábrázolás-mentés négyes mentén, változó sorrendben.
De terveim közt szerepel "rendes" GUI-k létrehozása is. Eddig arra jutottam, hogy Qt-t használok majd. Létezik hozzá egy Qt Designer nevű program, amivel a klasszikus drag'n'drop-pal tudod megtervezni a felületet (hasonlóan a LabView-höz vagy CVI-hoz). A program kimenete egy ui kiterjesztésű fájl. Ezt a Python programodba az alábbi kóddal - vagy ennek megfelelő módosításával - lehet beilleszteni (itt találtam):
import sys
from PyQt4 import QtGui, uic
class MyWindow(QtGui.QMainWindow):
def __init__(self):
super(MyWindow, self).__init__()
uic.loadUi('mywindow.ui', self)
self.show()
if __name__ == '__main__':
app = QtGui.QApplication(sys.argv)
window = MyWindow()
sys.exit(app.exec_())Innentől az UI elemeit a Python kódból tudod piszkálni. A szokásos csúszkák, gombok, kapcsolók mellett az egyik ilyen lehetséges elem a Matplotlib widget, tehát tulajdonképpen egy grafikon felületet integrálhatsz az UI-ba.
A fenti módszert már kipróbáltam és működött, de élesben még nem használtam. A WinPython nevű Python disztribúcióban minden benne van, de pl a cross-platform Anaconda-ban is szinte minden, a Qt Designer meg egy külön telepíthető program.
Számomra a "végső megoldás" egy olyan program lehetne, amiben a GUI elemek mellett egy nagyobb szövegmezőbe érvényes Python kódot lehet írni és futtatni, ezáltal egyesíthetném a GUI-alapú előre megírt programok előnyeit egy Python-féle szkriptnyelv rugalmasságával.
[ Szerkesztve ]
"We spared no expense"
-

boneyard
tag
Sziasztok!
Egy nagyker webshop termékadatlapjairól szeretném begyűjteni a készletszámokat. Ahhoz, hogy ezek megjelenjenek, előtte be kell jelentkezni.
Eddig VBA-s macron kívül mást nem írtam, úgyhogy googleből keresgéltem.Addig eljutottam, hogy letöltöttem a sitemap-ot, amiből kigyűjtöttem csak a termékadatlapok linkjeit.
Megírtam a scriptet, ahol a Selenium PhantomJS webdriver segítségével szépen bejelentkezik a nagyker felületre, aztán következik ez:driver.get('01-termékadatlap-linkje')
adatlap = driver.page_source
soup = BeautifulSoup(adatlap, "html.parser")
print soup.title.string
if (soup.find('span', class_='onStock') is not None):
print(soup.find('span', class_='onStock').string)
else:
if (soup.find('span', class_='outOfStock') is not None):
print(soup.find('span', class_='outOfStock').string)
else:
print('Megszűnt')Szépen megjelenik a title, alatta pedig vagy a darabszám, vagy Elfogyott vagy Megszűnt felirat.
Amit szeretnék, hogy ezt a részt megismételje az összes kigyűjtött adatlap linkkel és az eredményeket ne csak az ablakba printelgesse ki, hanem egy külön fájlba.Megoldható ez valahogy?
[ Szerkesztve ]
-
tvamos
nagyúr
válasz
cousin333
#559
üzenetére
Erdekes dolgokat irsz... Hmm...Azt irjak a honlapon:
Installing Jupyter and Python
For new users, we highly recommend installing Anaconda.
Azt hiszem, ezt fogom tenni.Bar, ha jol latom, a Qt Designer-hez nem kell. [link]
"Mindig a rossz győz, és a jó elnyeri méltó büntetését." Voga János
-
cousin333
addikt
A Qt egy C++ alapú keretrendszer GUI-k létrehozására. A Designer tudtommal az ő programjuk, így teljesen független a Pythontól.
Az Anaconda alapvetően egy jó disztribúció: tehát Python (2.7 vagy 3.5) + fejlesztőeszközök (pl. IPython, Spyder) + egy tonna külső fejlesztésű modul (numpy, scipy, matplotlib... stb.) vannak benne. Frissíteni, újat telepíteni meg a conda nevű, Linux csomagkezelőhöz hasonló programmal lehet.
Pl. telepítés:
conda install pyvisaMinden csomag frissítése:
conda update --allui: Az Anaconda elég nagy méretű, de van egy ún. Miniconda, ami csak az alapokat tartalmazza és a conda-t az esetleg hiányzó csomagok letöltéséhez.
"We spared no expense"
-

#82595328
törölt tag
Karakterkódolási problémám van.
Csináltam egy .csv fájlt Libreoffice Calc-ban. Ha az UTF-8 kódolást választom. Hiába szerepel a script elején a "# coding: utf-8" hogy UTF-8 az alapértelmezett kódolás. A beolvasott szövegben hibásak lesznek az ékezetes karakterek. Viszont ha a kelet-európai (ISO-8859-2) kódolást választom, akkor jó az import. Ezt nem igazán értem miért. A kérdésem pedig, hogy hogy tudnám helyesen UTF-8 kódolással beolvasni? -
#564
DrojDtroll
addikt
DrojDtroll
addikt
Valaki találkozott már olyannal hogy a .index() rossz eredmény ad?
-
#565
DrojDtroll
addikt
DrojDtroll
#564
DrojDtroll
addikt
válasz
DrojDtroll
#564
üzenetére
.split() maradt ki a fájl beolvasása után

-
#566
DrojDtroll
addikt
DrojDtroll
addikt
Szeretnék egy chat program szerű kinézetett a programomnak. Mivel lehetne megoldani legkönnyebben a buborékos kinézetett?
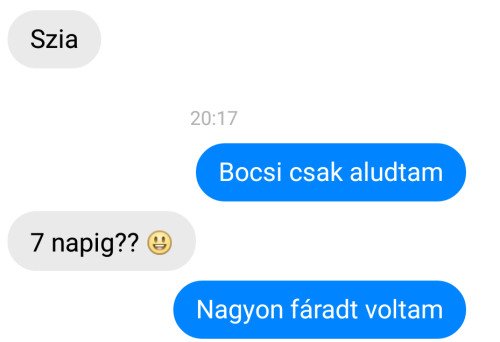
Valami ilyesmire gondoltam.
-
cousin333
addikt
válasz
 #82595328
#563
üzenetére
#82595328
#563
üzenetére
Egyáltalán mivel olvasod be? Kézzel, soronként? A csv modullal vagy valami mással? (melyik Python?)
Én a csv fájlokhoz (is) a pandas nevű modult használom. Jelen esetben talán kicsit túlzás, de amúgy sokrétűen használható. Van neki egy read_csv() metódusa, amiben sok egyéb mellett a kódolást is meg lehet adni.
A jelek szerint a LibreOffice mégiscsak kelet-európai kódolással ment (ahogy tipikusan az Excel is).
[ Szerkesztve ]
"We spared no expense"
-
#82595328
törölt tag
válasz
cousin333
#567
üzenetére
Kicsi szűkítem a problémát:
A hiba Windows 10-en futtatott Libreoffice 5.1.1.3-ból UTF-8 kódolással exportált .csv fájl esetén jelentkezik, ha Windows 10-en Python 3.5 IDLE-vel próbálom futtatni a scriptet. Ami vicces, hogy a scripet linux alatt jól jelenik meg az ékezetes karakter.
A kód kb. ennyi. Legalábbis a lényegi része.with open ('Lista.csv') as f:
f.readline()
for sor in f:
sor=sor.strip().split(',')Windows alatt ezt kapom:
[['NĂ©vĂ\xad', '1'], ['NĂ©vű', '10'], ['NĂ©vö', '100']]Ez pedig a lista:
Néví,1
Névű,10
Névö,100 -
#569
 csaszizoltan
csendes tag
#82595328
#568
csaszizoltan
csendes tag
#82595328
#568
csaszizoltan
csendes tag
válasz
#82595328
#568
üzenetére
decode() vagy encode(), nem szeretem az empírikus programozást, de nekem ez már olyan rafinált probléma, amit nem szívesen értek meg, ha mégis, akkor a Windows console ablak nem UTF-8-ban jelenít meg és ezért azt a decode-dal UTF-8-ból "vissza" kell konvertálni, kódolni. Ha tudod mi a base64-es kódolás, akkor
itt egy jó példa:szóval ez talán jó lesz
 :
:sor=sor.decode('UTF-8').strip().split(',')
[ Szerkesztve ]
- Kivel és mit iszik Orbán? - Tök mindegy! Sörös vagy boros, csak közel legyen Soroshoz.
-
#570
#82595328
törölt tag
csaszizoltan
#569
#82595328
törölt tag
válasz
 csaszizoltan
#569
üzenetére
csaszizoltan
#569
üzenetére
Köszönöm a segítséget! Ez nem oldotta meg.
Helyette a codecs modul lett a megoldás.
A kód így néz ki:
import codecs
with codecs.open ('Lista.csv','rU',encoding='utf-8')as f:
f.readline()
for sor in f:Így már működik Windows és Linux alól is.
-
#571
DrojDtroll
addikt
DrojDtroll
addikt
Próbált már valaki közülünk androidra fejleszteni pythonban?
-
#572
cousin333
addikt
DrojDtroll
#571
cousin333
addikt
válasz
DrojDtroll
#571
üzenetére
Pont ma néztem meg, hogy milyen lehetőségek vannak (bár elsősorban a kódfuttatás érdekelt). De kb. ennyi.
[ Szerkesztve ]
"We spared no expense"
-

XP NINJA
őstag
Sziasztok!
Van egy több ezer listából álló listám, melyeknek 5 tagjuk van. Van benne string is és integer is. Melyik a legegyszerűbb módja annak, hogy sorba rendezzem őket mindig a lista 3. eleme szerint? (Tehát a sok lista egyben maradna, csak a nagy listán belül rendeződnének.) Válaszokat előre is köszönöm!

-
#574
csaszizoltan
csendes tag
XP NINJA
#573
csaszizoltan
csendes tag
válasz
 XP NINJA
#573
üzenetére
XP NINJA
#573
üzenetére
Szia!
https://wiki.python.org/moin/HowTo/Sorting
Speciel a Key Functions fejezet alatt:console
>>> student_tuples = [
('john', 'A', 15),
('jane', 'B', 12),
('dave', 'B', 10),
]
>>> sorted(student_tuples, key=lambda student: student[2]) # kor szertint rendezve
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
>>> sorted(student_tuples, key=lambda student: student[1]) # nagybetű szerint rendezve # and by me
[('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
>>> sorted(student_tuples, key=lambda student: student[0]) # név szerint rendezve # and by me
[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]csak a tuples-ek helyett Nálad kis listák vannak, azon belül egy elemre hivatkozás ugyanúgy történik.
Az itt felhasznált lambda függvény különösebb értése illetve magyarázata nélkül javaslom.[ Szerkesztve ]
- Kivel és mit iszik Orbán? - Tök mindegy! Sörös vagy boros, csak közel legyen Soroshoz.
-
#575
EQMontoya
veterán
csaszizoltan
#574
EQMontoya
veterán
válasz
csaszizoltan
#574
üzenetére
Annyi megkötéssel, hogy ez nem in-place rendez, hanem le fogja másolni az eredeti listát, és kapsz egy másikat, ami rendezett. Pár ezer elemre nem para.
Same rules apply!
-
#576
XP NINJA
őstag
csaszizoltan
#574
XP NINJA
őstag
válasz
csaszizoltan
#574
üzenetére
Köszönöm, ezt olvastam, de a lambda miatt meg se próbáltam. De ajánlásodra megcsináltam és működik is.
Más: a kerekités függvényeket használtam már, de olyat még nem csináltam, hogy tizedes nélkülit kerekitsek megadott értékekre. Ez lenne a feladat: A jegy árának meghatározásakor az értéket öttel osztható számra kell kerekítenie. (1, 2, 6 és 7 esetén lefelé, 3, 4, 8 és 9 esetén pedig felfelé kell kerekítenie.) replace nem működik, mert integerről van szó.

-
cousin333
addikt
válasz
XP NINJA
#576
üzenetére
Szintén kerekíteni kell, de azt csak tizedesjegyekre lehet. A megoldás szerintem, ha ideiglenesen megduplázod a számot, tízesekre kerekítesz, majd kettővel osztasz (jobbra shifttel, mert a sima osztásnak nem biztos, hogy egész szám az eredménye). Példa:
In [9]: def kerekit(x):
...: return round(2*x, -1) >> 1
...:
In [10]: for i in range(20):
....: print('{}: {}'.format(i, kerekit(i)))
....:
0: 0
1: 0
2: 0
3: 5
4: 5
5: 5
6: 5
7: 5
8: 10
9: 10
10: 10
11: 10
12: 10
13: 15
14: 15
15: 15
16: 15
17: 15
18: 20
19: 20Jónak tűnik...
[ Szerkesztve ]
"We spared no expense"
-
#578
 MasterMark
titán
MasterMark
titán
MasterMark
titán
Üdv
Szöveges fájlban így vannak adatok:
1...
2...
3...
4...
X..
Y...
Z...A közepén bármennyi üres sor lehet.
Hogy tudnám ezeket szétszedni két tömbre?
Switch Tax
-
#579
 Karma
félisten
MasterMark
#578
Karma
félisten
MasterMark
#578
Karma
félisten
válasz
 MasterMark
#578
üzenetére
MasterMark
#578
üzenetére
Hol akadtál el?
Azért ez elég egyszerű beolvasás, amit meg lehet csinálni állapotgéppel vagy akár egymás után írt három ciklussal is (sor olvasás, amíg nem üres a beolvasott sor -> tömb 1; sor olvasás, amíg üres; sor olvasás, amíg nem üres -> tömb 2).
“All nothings are not equal.”
-
#581
Karma
félisten
MasterMark
#580
Karma
félisten
válasz
MasterMark
#580
üzenetére
Előirányzom, hogy nem vagyok nagy pythonos (a prog topik miatt vagyok itt), de pusztán stack overflow-val a következő kódot ütöttem össze pár perc alatt:
list1 = []
list2 = []
emptyLineFound = False
with open('test.txt') as f:
for line in f:
stripped = line.strip()
if stripped:
if emptyLineFound:
list2.append(stripped)
else:
list1.append(stripped)
else:
emptyLineFound = TrueA meglepetés számomra az volt benne, hogy for ciklussal végig lehet menni a fájl sorain, illetve egy üres string falsynak számít. A többi adja magát, ahogy korábban is beszéltük.
“All nothings are not equal.”
-
#582
MasterMark
titán
Karma
#581
MasterMark
titán
Köszi. Működik, bár nem teljesen értem.
Viszont mégsem jó valamiért.
Valaki esetleg nem tudja, hogy hogy lehetne szétválasztani reguláris kifejezéssel? Vagyis a számmal kezdődőt rakja az egyikbe, betűvel kezdődőt a másikba, üres sorokat pedig kihagyni. Bár az adódna a másik kettőből azt hiszem.
De ezt sem tudom, hogy lehetne megoldani pythonban...
Switch Tax
-
#583
Karma
félisten
MasterMark
#582
Karma
félisten
válasz
MasterMark
#582
üzenetére
Az előző kódom pontosan azt csinálta, amit mondtál: az üres sorok előtti blokkot az egyikbe, az utánikat másikba tette be. Nem mondtad, hogy nem a fogad fáj

Mondjuk ez se agysebészet. A ciklus, ami végigmegy a fájlon nem változik, csak a belső feltétel. A re modullal meg lehet mintaillesztést végezni.
import re
list1 = []
list2 = []
pattern = re.compile("\d+")
with open("test.txt") as f:
for line in f:
stripped = line.strip()
if stripped:
if pattern.match(stripped):
list1.append(stripped)
else:
list2.append(stripped)Egyébként nem tudom, melyik része nem világos. Célszerű pontosabban kérdezni. Ha esetleg a strip() a problémás, azt azért használtam, mert a sorokat úgy kapja meg a for ciklus törzse, hogy a sor végén egy újsor karakter ott marad. A sor eleji és végi whitespace lenyírásával biztos, hogy a hasznos szövegre futnak a feltételek.
“All nothings are not equal.”
-
EQMontoya
veterán
Same rules apply!
-
XP NINJA
őstag
Hali!
Érettségi feladatok között sosem találkoztam még függvénykészitéssel, és eddig el is voltam nélküle. De most kaptam egy ilyen feladatot:
Függvény szame(szo:karaktersorozat): logikai
valasz:=igaz
Ciklus i:=1-től hossz(szo)-ig
ha szo[i]<'0' vagy szo[i]>'9' akkor valasz:=hamis
Ciklus vége
szame:=valasz
Függvény végeTi hogy irnátok meg?
-
cousin333
addikt
válasz
XP NINJA
#586
üzenetére
Ez meg milyen leíró nyelv?
Azt kérdezted, én hogyan írnám meg. A válasz: sehogy, mert minek újra feltalálni a kereket, amikor van erre jó kis gyári függvény. Pl:
>>> szo1 = "Valami szöveg 123"
>>> szo1.isdigit()
False
>>> szo2 = "536 25"
>>> szo2.isdigit()
False
>>> szo3 = "53625"
>>> szo3.isdigit()
TrueHa viszont hűek akarunk lenni a példához - a Python nyelv elvárásain belül - akkor ezt írnám:
def szam_e(szo):
valasz = True
for betu in szo:
if betu < '0' or betu > '9':
valasz = False
return valaszA for ciklust mondjuk így is írhatnád:
for betu in szo:
if not '0' < betu < '9':
valasz = FalseVagy esetleg így:
import string
for betu in szo:
if betu not in string.digits:
valasz = FalseUpdate! Egy kis adalék: a saját megoldások futtatási ideje sorrendben 1,41, 1,61 és 1,55 us (mikroszekundum), ellenben a gyári függvénnyel 53,9 ns (nanoszekundum). Utóbbi tehát úgy 26-szor gyorsabb...
[ Szerkesztve ]
"We spared no expense"
-
Karma
félisten
válasz
cousin333
#587
üzenetére
Mondta: érettségi feladat.
Ez a leíró nyelv egyébként a nyolcvanas években elég népszerű volt.Az "Informatikai alapismeretek" érettségi vizsgán pedig mindig van egy olyan feladat, melyben egy ilyen pszeudokódot kell "lefordítani" a diák által választott nyelvre. Hogy ennek mennyi értelme van, az vitatható, de nem az a feladat, hogy fejtsd vissza és írd meg helyesen/gyorsabban az algoritmust, hanem tükörfordítást várnak.
[ Szerkesztve ]
“All nothings are not equal.”
-
cousin333
addikt
Az én is olvastam, hogy érettségi feladat. A pszeudokód fogalma is rendben van, csak fura volt a szintaktikája.
Nyilván hűen követni kell a leírást, de azt kérdezte, hogy én hogyan írnám meg

Ha ezt így érettségin elém adnák, valószínűleg a 2. megoldásomat adnám be. Vagy te máshogy írtad volna?[ Szerkesztve ]
"We spared no expense"
-
Karma
félisten
-
Szenty
tag
válasz
cousin333
#587
üzenetére
Esetleg úgy lehet picit optimalizálni, hogy a ciklusból kilépsz az első nem-szám karakternél:
def szam_e(szo):
valasz = True
for betu in szo:
if betu < '0' or betu > '9':
valasz = False
break
return valaszIlletve clean code-os körökben az is elfogadott, hogy a ciklusból adjuk vissza az eredményt (így a valasz változót ki is emeltem):
def szam_e(szo):
for betu in szo:
if betu < '0' or betu > '9':
return False
return True -
cousin333
addikt
Igen, ezek is teljesen jó megoldások és átlagosan még gyorsabbak is. De akár bevethetjük a Python egyik fura szintaktikai megoldását, amivel nagyjából a második algoritmusodat kapjuk vissza:
def szam_e(szo):
for betu in szo:
if betu < '0' or betu > '9':
break
else:
return True
return FalseMég jó, hogy a Pythonnál az egyszerűségre törekedtek, és minden problémára lehetőleg csak egy (praktikus) megoldás létezik.
[ Szerkesztve ]
"We spared no expense"
-
cousin333
addikt
válasz
 EQMontoya
#594
üzenetére
EQMontoya
#594
üzenetére
Először is, nincs benne ékezet, és ők is magyart használtak a pszeudokódban. Másrészt ez egy magyar fórumon adott segítség, az ilyesmi legyen a vizsgázó baja

Azért kíváncsi vagyok, mit szólnának ehhez, elvégre angolul van
![;]](//cdn.rios.hu/dl/s/v1.gif) :
:def isnumber(input_string):
ans = True;
for i in range(len(input_string)):
if ((input_string[i] < '0') or (input_string[i] > '9')):
ans = False;
return ans;[ Szerkesztve ]
"We spared no expense"
-

gt7100
tag
válasz
cousin333
#595
üzenetére
Itt ugyan nincs jelentősége, de általában (hacsak nem változott valami a python3-ban) célszerű range helyett xrange-t használni.
Hogy miért, arra talán a legjobb demo egyx=range (《elérhető memória mérete bájtokban/4》)
parancsot kipróbálni, majd ugyanezt xrange felhasználásával.
-
cousin333
addikt
Teljesen igaz, amit írsz, a Python 2-ben a range egy komplett listát hoz létre és azon iterál végig. Ugyanakkor - bár nem szoktam kihangsúlyozni, de - Python 3 párti vagyok (és minden kezdőnek ezt javasolnám), tehát nekem az az alapértelmezett, hacsak nem írom ki, hogy Python 2. Márpedig a Python3 egyik előnye, hogy elhagyták az i-s és x-es hülyeségeket, és az alap kulcsszó már magát az iterátort jelenti. Tehát van a zip a régi izip, és a range a régi xrange helyett. Tisztább, szárazabb, biztonságosabb érzés.
>>> for i in range(5):
... print(i)
...
0
1
2
3
4
>>> for i in xrange(5):
... print(i)
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'xrange' is not definedui: Ha valaki a régi megoldásra vágyik, mert sok a RAM-ja, természetesen az is elérhető:
list(range(10))
[ Szerkesztve ]
"We spared no expense"





























![;]](http://cdn.rios.hu/dl/s/v1.gif) :
:


Új hozzászólás Aktív témák

Állásajánlatok

Cég: Ozeki Kft.
Város: Debrecen

Cég: Alpha Laptopszerviz Kft.
Város: Pécs